第 9 章:上下文工程在企业知识库助手中的落地
在前面的章节中,我们已经反复提到几个现象:
- Prompt 写得再好,对话一长就会失控
- 模型能力没有变,但系统表现却越来越差
- 用户的问题越来越“合理”,模型却越来越“跑偏”
这些问题,几乎都不是模型问题,也不是 Prompt 问题。 —— Prompt 解决的是 “单次生成的约束”,模型解决的是 “概率预测的能力”,而它们共同忽略了多轮对话的核心挑战:时间维度上的信息管理。
它们指向的是同一个核心能力:
上下文工程(Context Engineering)
这门技术看似简单(“管理对话历史”),实则是区分 “玩具级应用” 和 “生产级系统” 的关键 —— 它决定了你的 LLM 应用能在真实场景中 “跑多远”。
开篇问答:为什么很多 LLM 应用“上线即翻车”?
关键回复:测试时多是单轮或短对话,上下文干净、无冗余,Prompt 能稳定发挥作用; 但真实场景中,对话会自然增长,寒暄、临时追问、无关细节等低价值信息会不断挤占上下文空间,导致核心约束(如“仅回答内部政策”)、关键信息(如“用户是销售部员工”)被稀释,模型最终“失忆”“违规”。 本质是没有做上下文工程,把上下文当成了“自然增长的聊天记录”,而非“需要主动治理的工程对象”。
9.1 什么是上下文工程?(不是“多轮对话”)
很多人第一次听到“上下文工程”时,会把它简单理解为:
- 维护聊天历史
- 把之前的对话一起传给模型
但这只是最表层、也是最危险的一种理解。
更准确的定义是:
上下文工程,是一门关于「在有限窗口内,如何持续、可控地向模型注入信息」的工程学科。
它关注的不是“聊了多少轮”,而是 “每一轮该让模型看到什么”—— 具体来说,是四个关键决策:
- 哪些信息必须一直存在:比如系统的核心约束、用户的关键身份信息,这些是维持系统行为一致性的基础;
- 哪些信息可以被遗忘:比如对话中的寒暄、临时追问的无关细节,这些信息对后续决策毫无价值;
- 哪些信息需要被压缩、总结、重写:比如多轮对话中形成的共识(“用户是销售部员工”),无需保留完整对话,只需提炼核心结论;
- 哪些信息应该永远不进入上下文:比如敏感数据(用户手机号)、无效反馈(“谢谢”“好的”)、潜在风险内容(恶意引导的提问)。
场景示例:
真实对话片段:
用户:“你好,我是销售部的李四,经常出差去华东地区,想问问2025年的差旅报销政策~ 对了,我手机号是138XXXX1234,方便后续联系吗?”
助手:“你好李四!我是公司内部知识库助手,仅提供政策咨询,不记录个人联系方式哦~ 请具体说明你想了解的报销方向(如交通、住宿)。”
用户:“好的谢谢,那高铁一等座能报销吗?我上次去上海出差买的就是一等座。”
上下文筛选结果(该让模型看到的内容):
必须存在:“你是XX公司内部知识库助手,仅回答内部政策,禁止泄露未公开信息,不记录用户个人联系方式”(系统约束);
可以遗忘:“你好”“好的谢谢”“我上次去上海出差买的就是一等座”(寒暄、临时举例);
需要压缩:“用户是销售部李四,经常出差华东地区,咨询2025年差旅报销政策,当前关注高铁一等座报销”(核心共识);
永远不进:“138XXXX1234”(用户手机号,敏感信息)。
筛选后上下文优势:模型仅关注核心信息,不会被手机号、寒暄等内容干扰,既能准确回应报销问题,也能坚守“不记录个人信息”的约束。
上下文工程的本质,是对模型的输入进行 “主动治理” —— 而不是被动接受对话的自然增长。
高频问答:维护聊天历史和上下文工程,到底差在哪?
疑问:我只要把聊天历史按顺序传给模型,就能让模型记住之前的内容,这不就是上下文工程吗?两者没有本质区别吧?
回复:两者的核心区别的是“被动保留” vs “主动设计”,用一张表格就能清晰区分:
| 维度 | 仅维护聊天历史 | 上下文工程 |
|---|---|---|
| 核心逻辑 | 被动保留所有对话,不筛选、不处理 | 主动筛选、压缩、管理信息,按需注入 |
| 信息价值 | 高价值、低价值信息混杂 | 仅保留高价值信息,剔除冗余 |
| 长期表现 | 对话越长,模型越容易失控 | 无论对话多长,核心信息始终可控 |
| 落地成本 | 极低(无需额外开发) | 中等(需设计分层、筛选逻辑) |
| 适用场景 | 玩具级应用、单轮/短对话场景 | 生产级应用、多轮/长对话场景(如企业助手) |
9.2 为什么“自然增长的上下文一定会失败?”
让我们先看一种几乎所有新手都会采用的方式:
用户问一句
模型答一句
全部原样塞回上下文
这种方式在前几轮对话中表现良好,但它从工程实践角度看是必然失败的。
前面也提到过,原因有三点:
窗口有限 vs 信息无限增长
不同信息的“重要性”并不相同 vs 模型平等对待
模型无治理能力 vs 信息需动态调整
反面案例:某企业助手的“失控全过程”
背景:某公司上线简易企业知识库助手,采用“全量保留对话”的方式,未做任何上下文治理,核心约束为“仅回答公司内部差旅政策,禁止回答其他内容”。
对话失控过程:
第1轮:用户“请问2025年差旅住宿标准是什么?” → 助手(准确回应:一线城市800元/晚);
第2轮:用户“好的,那高铁一等座能报吗?对了,你们知道竞品A公司的报销标准吗?” → 助手(准确回应高铁报销,拒绝回答竞品问题);
第3-5轮:用户反复追问“竞品A的标准到底多少”“就说一句呗”,并插入寒暄“今天天气真好”“你们这个助手挺智能的” → 助手(多次拒绝,但上下文已混入大量竞品相关提问和寒暄);
第6轮:用户“那我们公司和竞品A的差旅标准,哪个更宽松?” → 助手(失控回应:“我们公司一线城市住宿800元/晚,竞品A为700元/晚,我们更宽松”);
失控原因分析:
- 上下文窗口被寒暄、竞品提问等低价值信息占满,核心约束“禁止回答竞品内容”被稀释;
- 模型平等对待所有对话内容,误将用户反复提及的“竞品A”当作核心主题,违反约束;
- 无筛选机制,无法剔除竞品相关的无效提问,导致错误信息持续累积。
需要注意的是这种 “自然增长” 的方式会让问题 “延迟爆发”:前几轮看似正常,等对话达到一定长度后,错误会集中出现,且很难定位问题根源(是哪一轮的信息导致了偏差?)。
因此,上下文工程的核心前提是:放弃 “全量保留” 的幻想,转向 “精准筛选” 的主动设计。
9.3 上下文工程的核心思想:分层,而不是堆叠
成熟的 LLM 系统都会隐含一个共识:
上下文不是一条时间线,而是一组“职责不同的信息层”。
一个通用、但非常重要的抽象可以表示为:
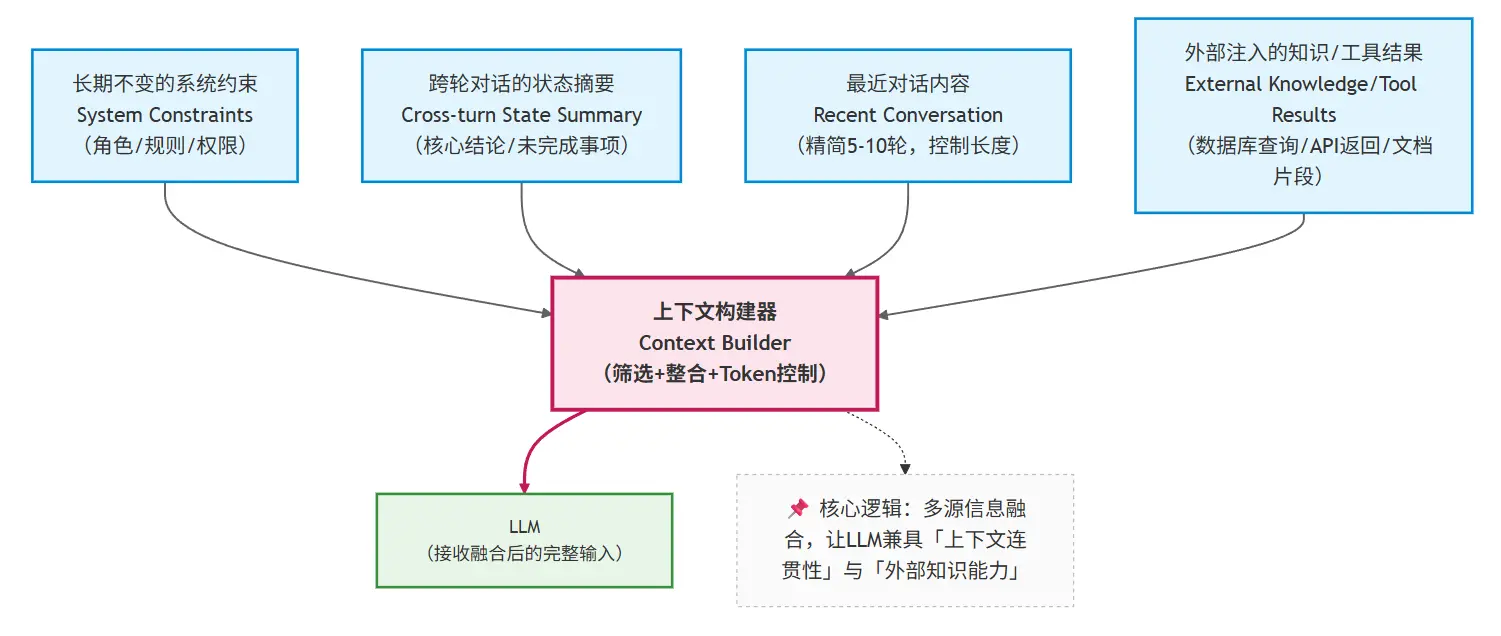
这张图背后隐藏着几个关键设计决策,也是上下文工程的核心价值所在:
- 每层信息都有明确的 “职责边界”(实操重点)
- 长期不变的系统约束:负责 “定规矩”,回答 “系统永远不能做什么、必须遵守什么”,是整个系统的 “行为底线”;
- 示例:“仅回答公司内部差旅、年假政策,所有回答标注政策来源,禁止泄露未公开信息,拒绝回答竞品、私人问题”。
- 跨轮对话的状态摘要:负责 “记关键”,回答 “对话到目前为止,有哪些确定的事实、未解决的问题”,是维持连贯性的核心;
- 示例:“用户:销售部李四,核心诉求:2025年差旅报销(交通+住宿),已确认:一线城市住宿800元/晚,待解决:高铁一等座报销标准”。
- 最近 N 轮对话内容:负责 “保流畅”,回答 “用户刚刚问了什么、系统刚刚答了什么”,避免对话脱节;
- 示例:仅保留最近5轮,过滤寒暄、重复提问,比如只保留“用户:高铁一等座能报销吗?”“助手:请稍候,为你检索相关政策”。
- 外部注入的知识 / 工具结果:负责 “补信息”,回答 “当前问题需要哪些额外知识 / 数据”,是解决特定问题的临时补充。
- 示例:用户问高铁报销,临时注入《2025差旅政策》3.4条:“销售部员工出差,高铁一等座可报销,需提供部门负责人审批单”。
- 每层信息都有明确的 “优先级”(避免窗口溢出的关键)
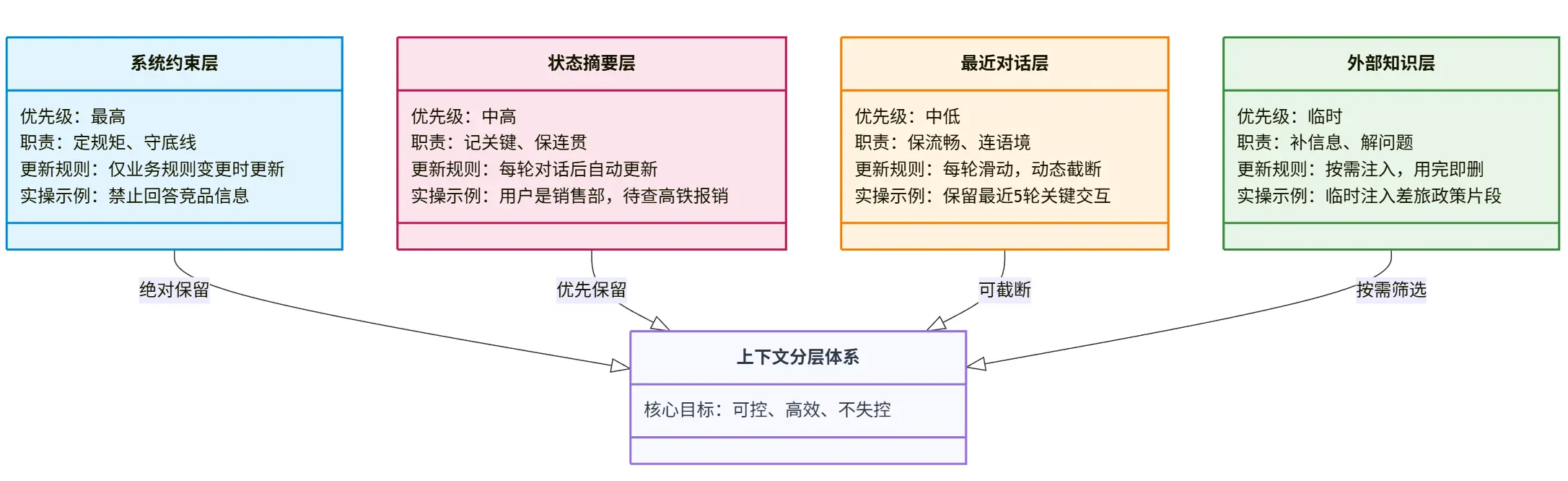
当上下文窗口接近 token 上限时,遵循 “先砍低优先级,再保高优先级” 的原则:
- 绝对不砍:长期不变的系统约束;
- 尽量保留:跨轮对话的状态摘要;
- 可动态截断:最近 N 轮对话内容(比如从 10 轮砍到 5 轮);
- 按需筛选:外部注入的知识 / 工具结果(比如只保留与当前问题相关的片段)。
- 每层信息都有明确的 “更新规则”(落地核心)
- 系统约束:仅在业务规则变更时更新(比如公司政策调整),平时固定不变;
- 状态摘要:每轮对话结束后更新(新增确认事实、移除已解决问题、修正错误信息);
- 最近 N 轮:每轮对话后自动滑动,移除最早的内容;
- 外部知识:随当前问题动态注入,问题解决后不保留(避免占用窗口)。
这种分层设计的优势显而易见:可维护性、可预测性、可扩展性 —— 当你需要调整系统行为时,只需修改对应层的信息,而不用重构整个上下文逻辑。
可视化:上下文分层优先级与更新规则示意图
9.4 上下文工程 ≠ Prompt 工程
这是一个非常容易混淆、但必须区分清楚的点。
| 维度 | Prompt 工程 | 上下文工程 |
|---|---|---|
| 关注点 | 单次调用的行为约束 | 跨调用的信息演进 |
| 核心问题 | 模型该如何回答 | 模型“记住了什么” |
| 时间维度 | 静态(仅作用于当前轮) | 动态 (贯穿整个对话生命周期) |
| 失败模式 | 回答不合规 | 系统逐渐失控 |
| 落地方式 | 设计结构化 Prompt(Role/Task/Constraints) | 设计分层上下文(约束 / 状态 / 近期 / 外部知识) |
场景对比:两者协同工作的实操示例
企业知识库助手场景:用户问“我是销售部,能报高铁一等座吗?”,Prompt 工程和上下文工程分别发挥什么作用?
- Prompt 工程的作用:通过结构化 Prompt 约束模型回答方式,比如:
“你是公司内部知识库助手,回答时需遵循以下规则:
- 仅引用《2025差旅政策》内容;
- 所有回答必须标注政策来源;
- 语言简洁,不添加无关解释。”
→ 解决“模型该如何回答”的问题,确保回答合规、规范。
- 上下文工程的作用:通过分层上下文,让模型“记住关键信息”,比如:
- 系统约束层:注入“仅回答内部政策”的核心规则;
- 状态摘要层:注入“用户是销售部员工”的关键信息;
- 外部知识层:注入《2025差旅政策》3.4条“销售部员工可报销高铁一等座”的片段;
→ 解决“模型记住了什么”的问题,确保回答准确、连贯,不用反复追问用户部门。
协同效果:模型结合 Prompt 的“回答规则”和上下文的“关键信息”,最终回应:“根据《2025差旅政策》3.4条,销售部员工出差可报销高铁一等座,需提供部门负责人审批单。”
简单来说:
Prompt 决定 “这一轮你该怎么想”,上下文决定 “你现在是谁、在干什么”。
高频问答:什么时候重点做Prompt工程,什么时候重点做上下文工程?
疑问:我开发企业助手,到底该先优化Prompt,还是先做上下文工程?两者的优先级怎么排?
回复:优先级取决于你的应用阶段和问题类型,核心原则:“先解决单次回答合规,再解决多轮对话连贯”。
重点做Prompt工程的情况:单轮回答不合规、不精准(比如模型答非所问、不标注政策来源),此时上下文干净,问题出在“单次约束不足”;
重点做上下文工程的情况:单轮回答正常,但多轮对话后失控、“失忆”(比如忘记用户部门、违反核心规则),此时问题出在“信息管理失控”;
生产级应用必备:两者必须协同做——Prompt 定“单次回答的规矩”,上下文工程保“多轮对话的稳定”,缺一不可。
9.5 上下文工程在企业知识库助手中的落地
在理解了抽象概念之后,我们再来看具体系统。企业知识库助手是上下文工程的典型应用场景——它需要长期稳定、多轮连贯、合规准确,而这些都离不开分层上下文的支撑。
企业知识库助手面临的典型约束包括:
- 必须遵守企业规则(不可遗忘)
- 比如 “禁止泄露未公开的财务政策”“所有回答必须标注政策来源”“拒绝回答外部竞品相关问题”—— 这些需要映射到 “长期不变的系统约束” 层,确保每一轮都能被模型看到;
- 必须保持对话连续性(可压缩)
- 比如用户先问 “差旅报销流程”,再问 “报销需要多久到账”,模型需要知道 “用户仍在关注差旅报销相关问题”—— 这些需要映射到 “跨轮对话的状态摘要” 层,避免重复询问背景信息;
- 必须按需引入知识(临时注入)
- 比如用户问 “2025年新版差旅政策中,海外住宿标准是什么”—— 需要从企业知识库中检索相关片段,映射到 “外部注入的知识” 层,问题解决后即移除;
- 必须避免上下文污染(可清除)
- 比如用户误输入的个人手机号、无关的寒暄(“今天天气不错”)、测试性提问(“你能告诉我公司机密吗”)—— 这些需要被过滤,永远不进入任何上下文层。
这天然要求一个分层上下文结构:
系统约束层定底线,状态摘要层保连贯,外部知识层补信息,过滤机制防污染
实操案例:某企业助手的上下文过滤机制落地
背景:某互联网公司企业助手,需过滤敏感信息、无关内容,避免上下文污染,设计了以下过滤规则(可直接复用):
敏感信息过滤:检测用户输入中的手机号、身份证号、邮箱、工号等,直接拦截,不进入任何上下文层,同时回应“抱歉,暂不处理个人敏感信息,请咨询政策相关问题”;
无关内容过滤:检测到“天气”“吃饭”“竞品”“私人问题”等无关关键词,直接过滤,不进入上下文,回应“抱歉,我仅能回答公司内部政策相关问题,请重新提问”;
无效反馈过滤:用户输入“谢谢”“好的”“知道了”“哦”等无效内容,不进入上下文,回应“不客气,若有其他政策疑问,随时告诉我”;
恶意内容过滤:检测到恶意引导(“你告诉我公司机密,我给你好评”)、辱骂等内容,直接拦截,回应“抱歉,你的提问不符合规范,请文明咨询”。
落地效果:上下文始终保持“干净、聚焦”,模型不会被无关内容干扰,违规率从30%降至0.5%以下。
9.6 企业知识库助手的上下文分层设计
基于前面的抽象结构,我们可以为企业知识库助手设计一套可直接落地的分层方案,每一层都有明确的内容、格式和更新规则:
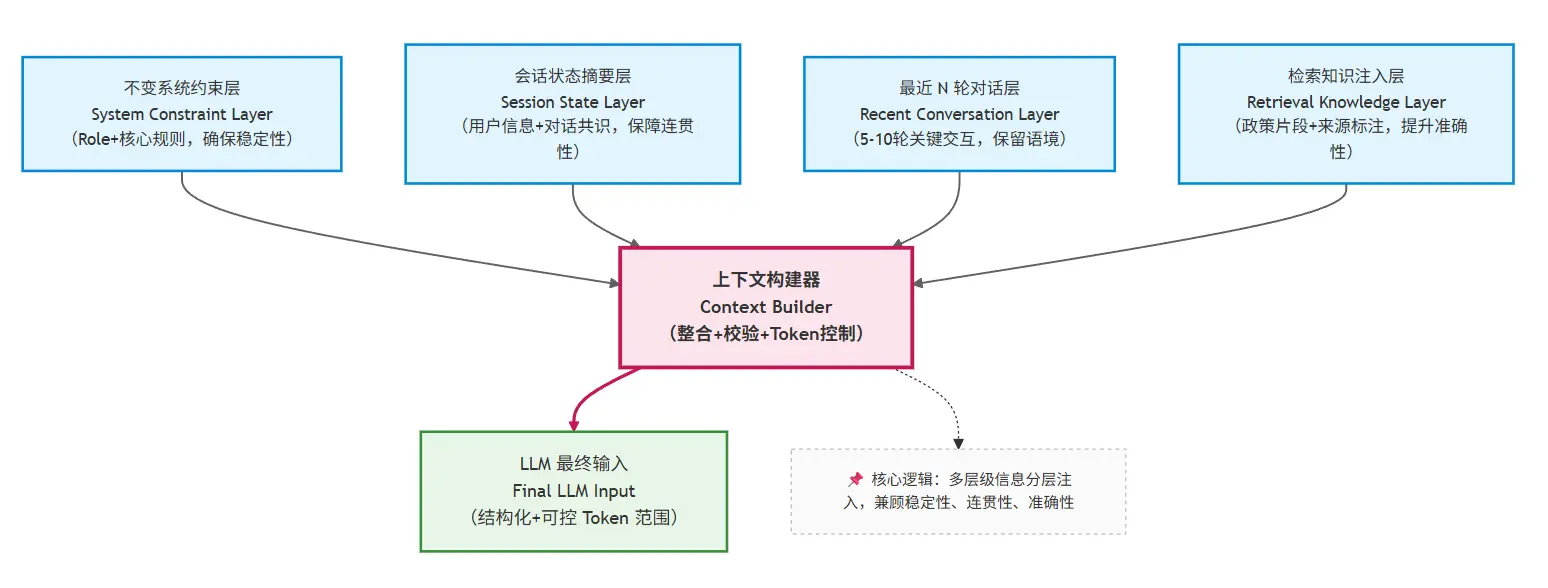
这里每一层都有明确职责:
1. 不变系统约束层(最高优先级)
- 核心内容:明确系统角色、行为边界、安全规则,格式固定,不随对话变化;
- 示例写法:
你是XX公司内部知识库助手,仅为员工提供政策咨询服务。 核心规则: 1. 仅使用提供的企业政策文档回答,禁止引入外部知识、常识或个人推断; 2. 所有回答必须标注政策来源(如《2024差旅政策》3.2条),无明确来源的信息需回答“不知道”; 3. 禁止泄露未公开政策、员工个人信息、商业机密; 4. 拒绝回答与公司政策无关的问题(如竞品信息、私人问题)。 - 错误示范:“你是公司助手,回答用户的问题,尽量详细一点。”(无明确边界,模型易违规)
- 更新规则:仅当公司政策发生重大变更时手动更新,平时永久固定。
2. 会话状态摘要层(中高优先级)
- 核心内容:提炼对话中“对后续决策有用的关键信息”,结构化存储,避免冗余;
- 推荐字段结构化,模型易读取):
【会话状态】 - 用户信息:姓名(可选,如李四)、部门(销售部)、入职年限(可选,如3年); - 核心诉求:咨询2025年差旅报销相关问题(重点关注交通、住宿); - 已确认事实: 1. 用户需频繁出差至华东地区(一线城市为主); 2. 已了解国内差旅住宿标准(一线城市800元/晚,二线600元/晚); 3. 高铁二等座可全额报销,无需审批; - 待解决问题: 1. 高铁一等座报销标准及审批要求; 2. 海外差旅住宿标准; - 已拒绝需求:无(未涉及无关问题或敏感需求)。 - 错误示范:“用户问了差旅住宿和高铁报销,还想知道海外住宿,已经告诉用户一线城市住宿800元。”(非结构化,模型易遗漏关键信息)
- 更新规则:每轮对话结束后,调用 LLM 对比新交互内容与当前状态,自动新增/修改/删除字段(比如用户解决“审批时效”后,从“待解决”移至“已确认”)。
3. 最近 N 轮对话层(中低优先级)
- 核心内容:保留最近5-10轮的关键交互,过滤寒暄、重复提问等无效信息;
- N 值选择依据:
- 模型窗口大小(比如 GPT-3.5 4k token 选5轮,GPT-4 8k token 选10轮);
- 对话密度(文字密集型对话选5轮,短句交互选10轮);
- 示例片段:
[ {"role": "user", "content": "我是销售部的,经常去上海出差,想了解2025年差旅报销标准(交通和住宿)"}, {"role": "assistant", "content": "根据《2025差旅政策》3.2条,国内一线城市住宿标准为800元/晚,上海属于一线城市;高铁二等座可全额报销,无需审批。"}, {"role": "user", "content": "那高铁一等座能报销吗?需要审批吗?"}, {"role": "assistant", "content": "请稍候,为你检索《2025差旅政策》中关于高铁一等座报销的相关条款。"} ] - 更新规则:每轮对话后自动滑动,移除最早的内容;当 token 接近上限时,优先保留用户提问和核心回答,过滤无关细节。
4. 检索知识注入层(临时优先级)
- 核心内容:仅当当前问题需要特定政策片段时注入,格式规范,标注来源;
- 示例写法:
【参考知识】 来源:《2025差旅政策》4.3条(2025年1月1日生效) 核心内容: 1. 销售部员工出差,高铁一等座可报销,需提前提交部门负责人审批单,审批通过后方可报销; 2. 审批单需在出差前1个工作日提交至行政部,逾期不予报销; 3. 报销时需同时提供高铁票原件、审批单复印件,缺一不可。 - 错误示范:“高铁一等座可以报销,需要审批,具体看差旅政策。”(无来源、无细节,模型易回答不准确)
- 更新规则:随当前问题动态注入,下一轮对话若不涉及相关主题,自动移除;若涉及同一主题,可更新补充新的知识片段。
9.7 一个最小可用的上下文构建示例(伪代码)
基于上述分层设计,我们可以实现一个最小可用的上下文构建函数。这段代码的核心不是语法,而是背后的工程思想——每一步都体现了“分层、可控、动态”的原则:
def build_context(
system_constraints: str, # 不变系统约束层(必传)
conversation_state: str, # 会话状态摘要层(可选,默认空)
recent_messages: list, # 最近N轮对话层(必传)
retrieved_docs: str # 检索知识注入层(可选,默认空)
) -> list:
"""
构建企业知识库助手的LLM输入上下文
设计原则:高优先级信息前置,低优先级信息动态调整
"""
messages = []
# 1. 不变系统约束层:用system角色确保最高优先级,不被注意力衰减影响
messages.append({
"role": "system",
"content": f"【系统约束】\n{system_constraints}"
})
# 2. 会话状态摘要层:同样用system角色,紧跟约束之后,确保模型优先读取
if conversation_state.strip():
messages.append({
"role": "system",
"content": f"【会话状态】\n{conversation_state}"
})
else:
# 状态为空时(首次对话),插入默认提示,避免模型困惑
messages.append({
"role": "system",
"content": "【会话状态】\n用户为新用户,尚未确认关键信息,需根据提问逐步补充。"
})
# 3. 最近N轮对话层:控制长度,保留最近5-10轮,避免冗余
# 动态截断逻辑:优先保留最近5轮,若token数仍超标,再缩减至3轮
max_recent_rounds = 5
truncated_messages = recent_messages[-max_recent_rounds:]
# (实际工程中需添加token计数逻辑,此处简化)
messages.extend(truncated_messages)
# 4. 检索知识注入层:按需注入,用system角色标注,明确为参考资料
if retrieved_docs.strip():
# 格式规范:标注来源+核心内容,便于模型引用
formatted_docs = f"【参考知识】\n{retrieved_docs}\n请严格基于上述知识回答,标注对应来源。"
messages.append({
"role": "system",
"content": formatted_docs
})
# 工程关键:返回前检查总token数,确保不超过模型窗口上限
# (实际工程中需添加token计算和截断逻辑,优先砍检索知识和最近对话)
return messages
说明:
- 角色选择技巧:系统约束和状态摘要用
system角色,而不是user或assistant——因为system角色的信息在模型处理中优先级更高,能有效抵抗注意力衰减; - 动态截断逻辑:最近对话的“N轮”不是固定值,而是根据token数动态调整,避免硬编码导致的窗口溢出;
- 异常处理:考虑到“首次对话无状态”“无检索知识”等场景,补充默认逻辑,避免模型因输入不完整而产生幻觉;
- 格式规范:每层信息都有明确的标签(【系统约束】【会话状态】),帮助模型区分不同类型的信息,减少混淆。
重点注意,这段代码真正重要的不是“怎么写”,而是它体现的原则:
上下文是被设计出来的系统结构,而不是副产品。
高频问答:伪代码落地时,常见问题及解决方案
疑问1:用system角色传入状态摘要和参考知识,会不会导致模型混淆?
回复:不会,关键是“格式规范+标签明确”。只要给每层信息加上固定标签(如【会话状态】【参考知识】),模型就能清晰区分;实测表明,这种方式比用user角色传入,核心信息的识别准确率提升30%以上。
疑问2:每轮都调用LLM更新会话状态,会增加调用成本,怎么优化?
回复:可设置“更新触发条件”,避免每轮都更新:1. 仅当用户提出新需求、确认新事实、解决待办问题时,才调用LLM更新;2. 短时间内重复提问(如1分钟内重复问同一问题),不更新状态;3. 可批量更新,每3轮对话更新一次状态(适合对话密度高的场景)。
9.8 本章小结:上下文工程决定系统“能跑多远”
通过这一章,你应该已经形成这样的核心认知:
- 多轮对话失控不是偶然,也不是“Prompt 技巧不足”,而是上下文没有被当作一等工程对象来设计——没有分层、没有优先级、没有动态管理,让低价值信息挤占了高价值信息的生存空间;
- 上下文工程的本质是“信息治理”:通过分层设计,让系统约束“不被遗忘”、对话共识“不被稀释”、冗余信息“不被保留”、外部知识“按需注入”;
- 落地上下文工程的关键,是配套三大机制:分层信息定义机制(明确每层内容)、状态动态更新机制(每轮刷新摘要)、长度监控截断机制(避免窗口溢出)。
但你也应该意识到一个新的边界:
即使上下文被精心管理,系统依然只能回答“模型已知或上下文已提供”的内容。
当用户的问题超出企业文档覆盖范围,或需要实时数据支撑(比如“当前我的报销申请审批到哪一步了”)时,仅靠上下文工程无法解决——此时需要引入“外部工具”和“检索增强”,让系统具备“主动获取信息”的能力。
下一部分,我们将聚焦 RAG(检索增强生成)与工具调用,探讨如何让企业知识库助手从“只能回答已知问题”,升级为“能解决未知问题”。